25 marzo 2010 Davide Magnan
Journal delle Esperienze
Incuriosito dalla notizia di youtube che utilizza l’HTML5 in sostituzione del più popolare Flash Player, ho voluto approfondire quali sono i nuovi tag utilizzati in questo linguaggio, che in teoria diventerà lo standard del futuro nella programmazione delle pagine web, e il ruolo che avranno per la visibilità nei motori di ricerca.
Novità dell’HTML5
Ecco un elenco di tutti i tag utilizzati nell’HTML5.
Vediamo nel dettaglio alcuni nuovi tag rilevanti per l’architettura delle pagine:
- <header>: rappresenta la testata di una sezione. Può essere usato più volte in una pagina, come intestazione di ogni singolo box;
- <footer>: come per l‘<header> può essere utilizzato più volte, con lo scopo di chiudere una sezione;
- <nav>: è la sezione contenente il menu di navigazione principale. Oltre a questo, può essere utilizzato per specificare i sottomenu ed eventualmente i link per scorrere gli articoli (avanti e indietro);
- <section>: definisce e separa la varie sezioni di un documento;
- <article>: questa è la sezione fondamentale. In essa infatti c’è il contenuto principale della pagina, quello che i motori di ricerca considerano più importante;
- <aside>: qui è riservato il contenuto correlato, come ad esempio le colonne laterali in cui è possibile specificare altri articoli dall’argomento simile.
Per rendere chiaro il loro utilizzo, vi mostro un esempio di Wireframe dell’HTML5 che ho trovato su Smashing Magazine.
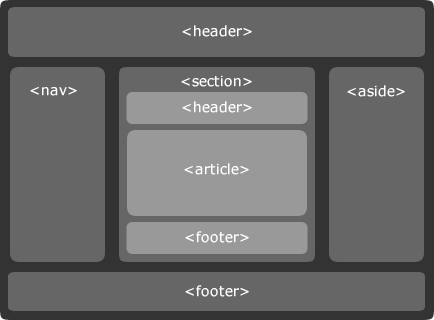
Come avrete capito, non si tratta di una vera e propria rivoluzione rispetto all’HTML 4. La definirei piuttosto una notevole miglioria della struttura semantica delle pagine.
In una struttura web semantica, i tag contribuiscono a definire il senso delle informazioni che contengono (titoli, immagini, testi, indirizzi, ecc.). Una caratteristica di un documento semantico è che si presta bene all’elaborazione automatica, ad esempio da parte dei motori di ricerca.
Evoluzione del linguaggio HTML
Per arrivare al livello di markup semantico possibile con l’HTML5, abbiamo superato varie fasi di “evoluzione”, che ci fanno anche capire come sarà il web del futuro.
In questo grafico ho riassunto le fasi più importanti:

Approfondiamo in dettaglio ciascun passaggio:
- Inizialmente (fase 1) HTML era un linguaggio di presentazione per il web, in cui facevamo ampio uso di table, frame, marquee, JavaScript e CSS inline. Gli unici metadati presenti allora erano i title, i metatag e gli headings.
- Successivamente (fase 2) siamo passati ad una maggiore separazione tra contenuto e presentazione. Abbiamo cominciato a includere script e fogli di stile esterni, rimpiazzato le tabelle con i div. Come risultato le pagine si sono alleggerite notevolmente e il contenuto testuale ha acquisito maggior peso rispetto al codice non rilevante.
- La fase 3 ha visto la comparsa di numerosi metadati: microformats, RDFa, microdata e XFN. Tra i più diffusi ci sono hCard, vCard, hProduct, hReview, vCalendar. Sono stati dei tentativi per specificare il significato delle informazioni riguardanti luoghi, attività commerciali, persone, prodotti e servizi, recensioni ed eventi. Per maggiori informazioni vi invito a leggere la documentazione sui microformats.
Nel caso degli XFN (XHTML Friends Network) invece, per fornire informazioni aggiuntive sulla relazione umana tra la pagina contenente il link e la pagina di destinazione. - La fase 4, con l’avvento dell’HTML5, vuole dare ancora più importanza semantica ai contenuti con lo sviluppo di un formato simile ai metadati. Infatti, una sua peculiarità è la somiglianza alla struttura dell’XML, uno dei metalinguaggi più diffusi.
Con l’HTML5 non si può ancora parlare di un web completamente semantico, però è chiaro che ci stiamo avvicinando ad un futuro in cui avremo un tag specifico per ciascun tipo di informazione e sarà possibile per un lettore automatico (browser o spider) comprendere il senso di un documento limitandosi a leggere la sua struttura. Per ottenere questo avremo bisogno di un codice molto più rigido e standardizzato di quello attuale, ed in questo senso la struttura scalabile e flessibile di XML sembra essere l’ideale per tale scopo.
Considerazioni finali: Google vuole i metadati
Questo processo di maturazione del linguaggio HTML agevolerà sicuramente i motori di ricerca, nell’identificare con precisione e facilità il contenuto veramente importante delle pagine.
In particolare ci sono molte notizie che fanno capire quanto Google ci tiene ad avere un web sempre più semantico:
- Uno dei curatori delle nuove specifiche, Ian Hickson, è un dipendente di Google;
- Google Chrome è stato uno dei primi browser a supportare l’HTML5;
- Google ha definitivamente abbandonato il progetto Gears in favore dell’HTML5;
- Youtube (di proprietà di Google) lo ha lanciato e sicuramente diventerà il player standard nel portale video;
- Da anni Google Maps supporta i metadati presenti nel microformat hCard;
- Le pagine dei risultati di ricerca di Google mostrano snippet con alcuni dati forniti da microformats e RDFa
- Da marzo di quest’anno anche i microdati sono supportati dai rich snippets
Avete notato anche voi che in tutte queste notizie Google è il protagonista? È evidente che l’intenzione è di promuovere tutti quei documenti che utilizzano i metadati.
Tutto sommato è una cosa logica…pensate per un attimo di dover leggere un libro privo di copertina, senza un indice degli argomenti e senza capitoli e sottotitoli. Se abbiamo tenacia e motivazione, riusciremo comunque a leggerlo tutto e impareremo tutto quello che c’è da imparare. Ma è evidente come tutti questi ausili, anche se non necessari, siano di sicuro molto apprezzati da noi lettori.
Allo stesso modo gli spider considerano i metadati un ottimo formato per organizzare le informazioni. Ripeto, non è qualcosa di necessario perché comunque i crawler hanno le capacità di spiderizzare intere pagine di codice, ma non è forse vero che lo scopo della SEO è anche quello di ottimizzare le pagine per i motori di ricerca? Ecco perché sarà compito di noi SEO architettare le pagine facendo un uso corretto dei nuovi tag, così da renderle più comprensibili possibile per il motore e valorizzarne il contenuto importante.
Ps. Un sentito ringraziamento ad Andrea Vit per l’aiuto che mi ha dato a scrivere questo articolo.