27 luglio 2006 Johnnie Maneiro
Journal delle Esperienze
Pochi giorni fa ho visto in tv un servizio sulle tarantole giganti del Venezuela, le più grandi del mondo, e subito ho pensato: bisogna tenere d’occhio questi ragni!
Mozilla – googlebot
Si parla molto dell’arrivo di una nuova generazione di spider più intelligenti,ma in realtà il dato notevole in materia di spider è il fatto che Google abbia cambiato lo useragent dal classico Googlebot in Mozilla-Googlebot, così come utilizzavano già la tecnologia Mozilla anche Mozilla-Slurp (lo spider di Yahoo) e altri browser come Firefox e Internet Explorer… gli altri browser?!! allora vuol dire che questo nuovo spider può emulare un browser? Personalmente penso di no, ma ancora non ho le prove tecniche, Mozilla è soltanto la tecnologia più idonea per interpretare contenuti sul web. Ma al momento, alla luce dei dati raccolti in 100 giorni di monitoraggio, posso solo dire che il nuovo Googlebot è più dinamico e decisamente molto più intelligente. In questo monitoraggio ho analizzato soltanto il traffico degli spider, quindi solo richieste automatiche, su un sito web di prova che indicherò come “site-x”.
Spider antispam
Site-x è sotto un dominio registrato da parecchi anni e con qualche centinaio di documenti tutti indicizzati in Google.
La prima intenzione di questo test era quella di provare la capacità degli spider di intercettare lo spam, e principalmente il cloaking. All’inizio c’era un’idea: l’ipotesi di uno spider “furtivo”, capace di viaggiare a fianco dello spider ufficiale per fare la stessa richiesta nello stesso momento e verificare se viene fornito lo stesso contenuto. Dopo qualche giorno il traffico in generale era aumentato notevolmente, anche a causa di alcuni fattori esterni, ma più di un mese dopo – quando le richieste degli spider erano aumentate senza che aumentassero però in uguale numero altre richieste da useragent sconosciuti, strani o browser simulati – l’ipotesi iniziale non è stata confermata. E in effetti non avrebbe senso!! In quel modo gli spider genererebbero traffico inutile verso i siti e una complicazione non da poco nei log. Quindi, abbiamo provato che non è lo spider a identificare lo spam, lui fa il suo lavoro di ricerca dati.
La velocità degli spider
Tante volte ho sentito dire: “lo spider non passa da qualche giorno!”… sicuramente sulla base della cache di Google, che viene aggiornata a intervalli, ma in realtà lo spider passa più spesso di quanto appare nella cache. In site-x lo spider passa regolarmente tutti i giorni e tante volte, così tante che si potrebbe parlare di velocità all’ora ma… non vorrei esagerare! Qui sotto una tabella con la media giornaliera delle visite dagli spider:
| Yahoo-slurp | 215 sr/g |
| Googlebot | 212 sr/g |
| Msnbot | 23,9 sr/g |
| Virgiliobot | 13 sr/g |
(sr = spider request)
Può far sorridere parlare di “velocità spider”, ma è proprio così, i dati sono verificabili. Ho registrato ogni dettaglio, fasce orarie e quant’altro in modo da poter rispondere a mille domande e confrontare i dati con i log poiché il monitoraggio è stato fatto con un sistema ad hoc parallelo ai registri dei log del web server.
Nel grafico qui sotto, invece, le visite (in %) ricevute dai vari spider nei 100 giorni dell’esperimento:
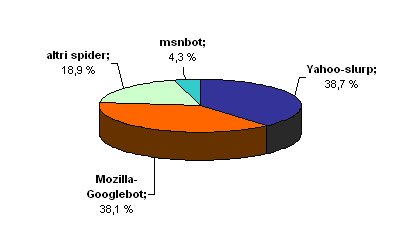
Analizzando più in dettaglio le visite degli spider a site-x, emerge che:
a.- La home è in assoluto la pagina più visitata dagli spider (ovvio, vero?), con 2.674 visite in 100 giorni, ha una capacità di aggiornamento molto alta nei motori di ricerca, e qualsiasi modifica fatta in questa pagina richiede solo poche ore per apparire nei risultati (24 ore in Google ad esempio)
b.- La seconda sezione più visitata, con 1.030 visite in 100 giorni, è quella che viene aggiornata più frequentemente come contenuto e con l’aggiunta di nuove pagine, cioè quella delle News, sicuramente dovuto al fatto che questa sezione ha un feed rss. Si possono aggiornare le pagine di questa sezione oppure crearne di nuove e trovarle 48 ore dopo nei motori di ricerca.
Spiderizzazione e posizionamenti
A questo punto una conferma: è importante monitorare il traffico dagli spider e cercare di mantenere un ritmo stabile delle visite automatizzate, ad esempio aggiornando regolarmente il sito, per aumentare le possibilità di posizionamento.
La spiderizzazione consiste in un’ondata di richieste automatiche che portano informazioni ai motori di ricerca. Quando un sito è visitato dagli spider per la prima volta, si crea un rapporto “quasi” indissolubile tra gli stessi, ma da questo momento in poi riproporsi sempre aggiornati agli spider diventa vitale.
La frequente spiderizzazione è fondamentale perché da questo evento dipende la natura propria dei motori di ricerca, cioè l’aggiornamento continuo dei contenuti presenti nei motori, altrimenti ci sarebbe il rischio di trovare nelle SERP sempre gli stessi risultati e addirittura il nostro lavoro non avrebbe senso.